Architecture - The top most partitions in a systems, their purposes and relationships.
Architecture Driven - Software is architecture driven, but projects are risk driven.
Capability Maturity Model - A 5 level model describing an organization's process maturity.
Declarative Knowledge - "Pure data" representing what to do. It separates what from how.
High Cohesion - A class or subsystem does one thing and does it well.
Layered Architecture - A system is partitioned into layers, each calling downward.
Likeability Testing - Likeablity is the single most important measure of how good a system is.
Loose Coupling - Low dependencies allow collaborating objects to vary independently.
Modeling - The single most important step in the software development cycle.
Partition - Systems are divided into strategic partitions, each of which is a class or subsystem.
Patterns - A pattern is a resuable solution involving collaborating roles.
Plugpoint Framework - Allows building system by plugging in components at plugpoints.
Process - A systematic series of steps to do something well.
Reuse - The key to ultra high productivity is ultra high reuse. Even process is reuse.
Risk Driven - Software is architecture driven, but projects are risk driven.
Role - Describes what type of work a component does. Roles are reusable.
Service Architecture - A system uses independent reusable "services" for generic work.
Simplicity - Keeping all aspects of software conceptually simple pays big dividends.
Unit Test - Each components must pass a unit test before being added to the system.
Use Case - Describes how an actor uses a system to accomplish a goal.
Architecture - The top most partitions in a system, and their purposes and relationships, are the system's architecture. Ivar Jacobson recommends only 2 to 4 such partitions. Examples are GUI, Business Logic, Persistence and Inter-System Communication, which is a popular scheme. Please note that while your architectural model may have a dozen or more classes or subsystems, these elements are grouped into partitions. Each partition is independently modifiable or replacable. As one drills down each subsystem has its own architecture, though this becomes less and less important. What architecture you use depends on your architectural goals, such as extensibility, distributed deployment, reuse, robustness and understantability.
Architecture Driven - Sadly enough, most software is schedule or requirements driven. Better is architecture driven, where the architecture is designed first and the product second. As the product is developed or modified, the guiding force is carrying out the grand architectural mission. Many products can use the same or similar architecture. Software should be architectural driven, while projects should be risk driven. When looking at an unfamiliar piece of software, the first question to ask is "Is it architecture driven?" I adopted this philosophy from Grady Booch.
One could easily counter "Why shouldn't a project be schedule and requirements driven? Isn't this far more important than architecture?" Ahhhh, we must explain a bit here. For short term results a project should only address its own schedule and requirements. But consider the average organization, which has many products with long lifetimes and many projects building those products. To maximize long term benefits we create reusables that can be shared by products. Most of these reusables are tangible pieces of software that can best be reused if a product has a standard architecture and uses as many standard components as appropriate. At the strategic level a project is putting that reusable architecture and components into the product, and at the tactical level the project is following the schedule and requirements.
Of course, all this assumes the chosen architecture is appropriate. We must remember that architecture, especially if new technology is involved, is a high risk product itself and needs the same attention any other important product gets.
Capability Maturity Model (CMM) - As defined by Watts Humphrey of the Software Engineering Institute (SEI), all software organizations have 5 levels of process maturity: Initial, Repeatable, Defined, Managed and Optimizing. About 75% are at level one, aka Chaos Canyon or Unpredictable. It takes 2 to 3 years to advance one level, and levels cannot be skipped. Each level, in the author's opinion, increases productivity by a factor of 2 to 5. Though invented for DOD contractors, the CMM is valid for nearly all software shops. The main strategy is formal continual process improvement. However, this is no substitute for common sense....
To adopt the CMM, you first get super committed. Then you do a self audit or have a consultant do one. This tells where you are on the maturity scale. Given that level, there are certain exact best practices to adopt that have been shown to give results quickly to advance to the next level. For example if you're at level one, your goal should be to first achieve some predictability of schedules and cost. This can be done by very precisly by adopting tight project management, defect control and configuration management.
Declarative Knowledge - From the field of Artificial Intelligence we have Declarative Knowledge (DK), which is pure data representing what to do. DK contains no behavior whatsoever. That is provided by the Expression Engine, such as a browser's rendering engine for HTML. DK separates what to do from how to do it, a very fundamental abstraction. Nature likes this abstraction too, as we can see from the incredible leverage of DNA.
Making up only a tiny fraction of nearly all life, DNA provides the instructions for protein synthesis, which controls enzyme activity, and thus every aspect of cell function, and thus everything the organism does. Using a process called transcription, strands of RNA copy and carry instructions from the DNA to the site of protein synthesis in the cell's cytoplasm, where translation of the instructions to amino acids occurs. There is much food for thought here....
The moral of this story is intent must differ from expression, ie what to do must be cleanly abstracted from how to do it. In the Bean Assembler, parex files are the what and ParamDriven reusable classes are the how. As the software industry matures, we will write less code and more intentions, with the help of sophisticated visual/audio tools.
High Cohesion - Cohesion is how closely related the functions performed by a component are. A component with high cohesion would have a narrow mission, and is easy to compose systems with. One with low cohesion would provide behavior is a variety of areas, and tends to be harder to understand, harder to reuse, and bigger. High cohesion is better. As I often say, "A class should do one thing and do it well." The same is true for subsystems.
From "201 Principles of Software Development" by Davis, page 86:
Coupling and cohesion were defined in the 1970s by Larry Constantine and Edward Yourdon. They are still the best ways we know of measuring the inherent maintainability and adaptability of a software system. In short, coupling is a measure of how interrelated two software components are. Cohesion is a measure of how related the functions performed by a software component are. We want to strive for low coupling and high cohesion. High coupling implies that, when we change a component, changes to other components are likely. Low cohesion implies difficulty in isolating the causes of errors or places to adapt to meet new requirements. |
Also see Loose Coupling.
Layered Architecture - At the architecture level of modeling, this is probably the most important pattern. In the Layered Architecture Pattern, you partition the system into vertical layers. Each layer can only use the layer below it. The lower layer classes or subsystems are fewer in number and more stable. Upper layer elements are greater in number and less stable. This makes a layered archtecture system look like an inverted pyramid. A typical example is GUI, Business Logic and Communication layers, as shown below.
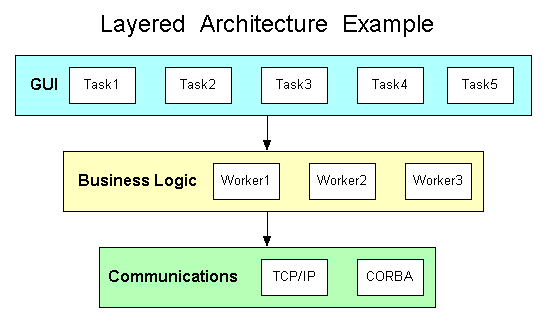
![]() The main advantage is changes to an upper layer cannot "break"
a lower layer. For example we might change a Business Logic class to reflect
the latest company policy, and inject a bug. Neither the policy change nor
bug could possibly cause the Communications layer to stop working properly.
An exception to this is if an upper layer left a lower layer in a "bad
state", which in practice is rare. Good design will reduce this, but
to be honest cannot eliminate it completely in all cases.
The main advantage is changes to an upper layer cannot "break"
a lower layer. For example we might change a Business Logic class to reflect
the latest company policy, and inject a bug. Neither the policy change nor
bug could possibly cause the Communications layer to stop working properly.
An exception to this is if an upper layer left a lower layer in a "bad
state", which in practice is rare. Good design will reduce this, but
to be honest cannot eliminate it completely in all cases.
![]() Another advantage is many elements can share lower layer elements.
For example many Business Objects needing server data use the Communications
layer to get that data.
Another advantage is many elements can share lower layer elements.
For example many Business Objects needing server data use the Communications
layer to get that data.
![]() Yet another advantage is lower layer blocks are reusable. A "lower
layer block" is several layers, starting with the lowest layer. For example
the Communications layer is reusable for many other systems. The Business
:Locic and Communications layers can be reused for a product with a different
GUI.
Yet another advantage is lower layer blocks are reusable. A "lower
layer block" is several layers, starting with the lowest layer. For example
the Communications layer is reusable for many other systems. The Business
:Locic and Communications layers can be reused for a product with a different
GUI.
![]() One more advantage is layers can play reusable roles. For example the
GUI, Business Logic and Communications layers are very reusable roles. Another
example is Application, Business Domain, Infrastructure, and MicroKernel layers.
One more advantage is layers can play reusable roles. For example the
GUI, Business Logic and Communications layers are very reusable roles. Another
example is Application, Business Domain, Infrastructure, and MicroKernel layers.
There are variations:
- Often a lower layer will need to call upward. This should be allowed only with a loose coupling mechanism such as event objects and event listener interfaces.
- A layer can call any layer below it, not just the one immediately below. This should be minimized, since the model becomes less understandable, and it becomes harder to replace layers independently because other layers may make different assumptions or it's harder to find what is calling a layer.
- The system may be partitioned into Layers and Services. Here any layer can use any service. This is similar to global variables, but more controlled since the services are well encapsulated and their roles are clearly defined.
See Appropriate System Architecture for a discussion of some issues.
Likeability Testing - Here we go beyond Usability Testing, which uses average users to test how easy a system is to use. We want a higher level of testing - How much does the user really like the system? This more closely relects the "user experience" and attempts to crack the very tough problem of the inhuman (and hence unfriendly and hard to use) interface that computers present to people. Likeability is more important than ease of use, because this is the impression the user is left with, and affects their performance when using the system. An unhappy user on an easy to use system gets less done than a happy user on a harder to use system.
Loose Coupling - Coupling refers to the dependencies between things or objects. The less objects are dependent on each other, the more they can vary independently, and hence the more different objects they can be used with, which is good. Collaborating objects always have some dependencies, otherwise they could not collaborate. The trick is to make these dependencies "loose", so that collaboration can occur but the objects can vary independently as much as possible. Some of these technical tricks are:
- Anonymous Collaboration, such as with events or messages.
- One way links, such as in Layered Architecture.
- Java interfaces, where the class type can vary.
- Inheritance, where the subclass can vary. Minimize the use of this, since in intriduces tight coupling between the super and subclasses.
- Fascades, which encapsulate an entire subsystem.
- Declarative Knowledge, which separates what from how.
- Reduction of responsibility, which reduces dependencies since the object does less.
- Policy and other role properties, which allow some dependencies to be replaced.
- The use of literal identifiers instead of public constants. The assumption is still there but the class dependency is gone. Meaningful Strings are typically used for this.
The benefits of loose coupling are huge and include:
- Higher reuse, which causes lots of beneficial side benefits.
- Higher productivity.
- Building systems from parts becomes far more possible.
- More robust systems, because failures cascade less.
- Fewer bugs, because more reuse means what is reused needs less testing.
- The ability to use CASE tools more, since through indirection they can control elements.
- More complex systems become humanly possible to build, due to higher reuse.
- Easier enhancement, modification and bug fixing, because parts can be worked on or replaced in isolation.
- Entirely new tpes of architectures can be used, such as Micro Plugpoint Role Frameworks.
Loose Coupling is also called Low Coupling. Also see High Cohesion.
Modeling - Models visually represent systems at a much higher level of human abstraction. Once you've done several hundred models and implementations, and have been seeking to improve your results with lots of iterations, patterns and assorted best practices, you begin thinking at a higher level. It's a mind switch that is impossible to describe but easy to achieve, if you hang in there. Once you're truly there, modeling becomes the romantic heart of software. It's where an avalanche of needs and lifetimes of experience reach a pinnacle of expression, and subsequent coding becomes trivial. When you're coding you need to be thinking at the model level. As I often say, the battle is won or lost in modeling.
Please checkout the Modeling Checklist. The checklist questions are educational in themselves.
Partition - Many developers and books fail to partition at the system level. Partitioning is dividing systems into groups of elements, and treating those groups as subsystems, aka partitions. This allows top down decomposition, where a system is successively designed at a finer and finer level until you reach the bottom. Good partitions have a Fascade and can be replaced easily, such as with a version change, rewrite or a different COTS implementation. Partitions collaborate using strictly defined loose coupling mechansisms, such as interface methods, events, blackboards and streams.
Mature partitions follow reusable roles. These should be identified and your system designs should be limited to them. This is a good place to start getting serious about the use of roles.
Perhaps the most important decision a designer ever makes is how to partition a system. Examples of historic partitions are the Java Virtual Machine, 2 tier client server, 3 tier client server and browsers.
Patterns - A software pattern is a reusable solution involving collaborating roles. This is not code reuse, but concept reuse. Patterns are a reuse mechanism. Once you intuitively understand patterns and know several dozen, you can model faster and better by reusing patterns appropriately. The use of patterns was established in 1995 by the Design Patterns book, which is an excellent place to start. I look forward to a Java version of this book.
Each element in a pattern plays a role. For example a Family Pattern has a father, mother, children and ancestry. The roles are father, mother, child and ancestor. Often patterns are related. For example the Hierarchy Pattern has Container and Member roles, and each Container has a Parent. The Family Pattern fits within the Hierarchy Pattern. If your reusables were implemented at the Hierarchy Pattern level they would be more reusable. It's important to use the most appropriate pattern, not the first one encountered.
Every designer has favorite patterns. Mine include MVC, Event Listener, Plugpoint Framework, Layered Architecture, Service Architecture, Class Factory, Declarative Knowledge, Polymorphic Event, Fascade and Role Framework.
Minimize inventing or naming your own new patterns. There are thousands out there already. We need to preserve a common pattern language.
Plugpoint Framework - A plugpoint is a predesigned point in a system for plugging in the desired behavior. A Plugpoint Framework (PF) has one or more plugpoints plus built in system behavior.Without the supplied plugpoints the system will not run. Once the plugpoints are supplied the system will exihibit behavior that is centered around the plugpoints. A good example of a PF with a single plugpoint is Java Applets.
In Java a plugpoint is an interface or subclass. The best approach is to use an interface and if appropriate offer a default standard implementation. Since this plays a "standard" role, I use the class name suffix "Std", such as TaskStd.
A lightweight PF has very little built in behavior. For example all it may provide is the ability to organize classes, create instances, start and close the system, and let plugpoints collaborate. Examples are Applets and Servlets. A heavyweight PF provides lots of built in behavior. Most popular frameworks are heavyweight and are highly configurable. Examples are SAP and PeopleSoft. These are currently not interface plugpoint style, but parameter driven by table data. They are moving towards partitioning into subsystems, using interfaces for all subsystem collaboration, and allowing customization via plugpoint substitution for some of the interfaces or subsystems, plus the table parameters. This will allow a component approach, since each plugpoint is for a component. This is all part of the Component Based Development (CBD) bandwagon.
My most successful PFs are simple, and use Layered Architecture with one or two plugpoints per layer, though not all layers have plugpoints and not all PFs use perfect layering. This allows a system's architecture to be expressed quickly in a very understandable manner. I'm rapidly coming to the conclusion that most new medium or large system design should use PFs. Here are the steps to create a PF:
- Do a brief high level analysis of several systems that will use the framework.
- Do a complete Plugpoint Framework analysis and get to the High Level Design step.
- State your Architectural Goals. These will emanate from Use Cases, Traits and Risks.
- Partition the system into layers. Strive for reusable layers.
- Identify the potential plugpoints in each layer and name them.
- Working with your Use Cases, fill in the plugpoint interface methods.
- Provide mechanisms for upper layers to get lower layer instances.
- Provide a ( preferrably reusable) mechanism to startup, run and close all the layers.
Here's a model showing an ultra simple hypothetical PF. Notice how notes are used to describe the architecture, and the use of the Context Pattern. The example is not complete but is illustrative.
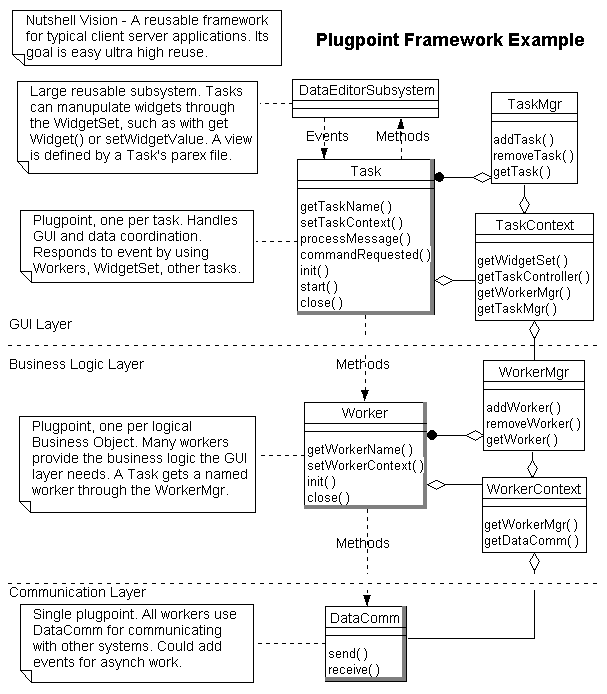
Process - A process is a systematic series of steps to do something well. All progressive software shops either have a formal process or are trying to adopt one, because the track record of those who have adopted good processes is now too strong to ignore. Since process is so important we have explored it in several separate documents.
Reuse - Reuse is the practice of building something once but using it many times. For systems this means using the same thing in many different places. This "thing" may be a method, class, subsystem, procedure, document template, guideline, hardware, etc. Thus reuse affects everything one does and produces. Reuse is a mindset, not a technique.
Reusable software elements are known as components. The grand goal is to easily assemble systems from components. Therefore we discuss reuse from a component perspective.
The high level technical contributors to reuse are, in approproximate order of importance:
- The framework the component lives in.
- The usefulness of a component in the desired context.
- Ease of correctly configuring a component to behave as desired.
- Ease of understanding how to reuse a component.
- Ease of locating an appropriate component.
- Ease of putting a component into the system.
Nearly all the Best Practices presented here will directly increase reuse.
There are levels of reuse, from small to large, such as local methods, static methods, classes, small subsystems and large systems. It is important to realize that you cannot hit high levels of reuse, ie over 90%, until you are reusing entire systems. Since reuse in the large requires system reuse, large systems are best built from components, and that requires an architecture that strongly supports reuse, it follows that reuse is a byproduct of good architecture. There is no need for a "Reuse Department" - good architecture and a decent component repository can do most of that. It also follows that larger components are better. For example the housing industry could skyrocket its productivity if it installed configurable pre-built houses, instead of building them from scratch each time. (This has been tried. Buyers want unique looking homes, plus the pre-fabs looked awful.)
Role - Each class or subsystem should play one or more defined roles. A role describes what type of work something does, at a higher level of abstraction than a class. For example you might be a mother, employee and singer. The advantage of roles is a system may be designed first at a higher level using standard roles, and then at a lower level using specific classes or subsystems. The standard roles themselves become reusable, leading to higher class or subsystem reuse. Roles are always part of patterns, though the pattern is not always understood. As your models become role driven you will find yourself designing role structures first.
Examples of generic software roles are Store, Collection, Carrier, Policy, Rule, Definition, Algorithm, Plugpoint, Fascade, Widget, Model, View, Controller, Event, Message, Factory, Transport, Initial State, Role, Workflow, Schema, Entity, Director, Mediator, Container, Description, Event Source and Event Reactor. There can also be more application or domain specific roles, such as Consumer, Consumer Item, Producer, Catalyst, Publisher, Registry, Instrument, Feature and Avatar. Note how most of these are never a class name.
A useful way to show roles in modeling is to put the role name(s) near the class or subsystem, or use it as a stereotype. You can also use name suffixes, such as WorkerMgr, TaskStd, EntityDef, LockPool, WidgetSet, GeneralLib, PropertyMap, ControlFactory, ParamSupplier, ListEditTest, LockService or ActionEvent.
Service Architecture - more - A system uses independent reusable "services" for generic work.
Use Case - A use case has a goal, a name, one or more actors, and a series of steps to achieve the goal. Often the name is the same as the goal. An actor is a user type who uses the system. Pioneered by Ivar Jacobson, they have these advantages:
- Thy express requirements in the user's terms, and serve to educate the analysts.
- They express requirements from the user's perspective, not the analyst's.
- They can be created by joint analyst/user sessions, or even by trained users.
- They can be validated by stepping through them, in effect animating the system.
- They can be understood by users
- Users can validate them.
- They can be mapped directly to design and testing.
- They serve as fertile ground for class and method identification.
- "Satisfies all use cases" can be exit criteria for the design, implementation and testing steps.
Because of all this use cases have proven to be the best way to express most system requirements, particularly in object oriented designs. Well written use cases are wonderfully clarifying. System development can be somewhat use case driven.
Use cases also serve as an easy bridge between requirements and design. That's because as you collect what the user wants to do, the use case steps capture how the user wants to do it, which is really designing how to achieve the use case goal. Some have condemmed use cases for being premature design, but properly used this is no problem.
If you find your use cases slipping into design too much or too early, use high (aka essential) level use cases first and low (aka real) level use cases later. High level use cases describe only what the user is trying to do and abstractly how the system helps them do it. They are fairly free of specific technology or implementation details, and are more stable. Low level use cases describe exactly how the user interacts with the system, complete with solution details such as GUI widget types, the technology used and report layout. I don't use the terms Essential and Real because they are confusing.
In large systems most use cases are between subsystems and involve no humans. Here the actors are systems. Beware that much popular and introductory literature assumes the actor is human.